HDFS全稱是Hadoop Distributed System。HDFS是為以流的方式存取大文件而設計的。適用於幾百MB,GB以及TB,並寫一次讀多次的場合。
構成HDFS主要是Namenode(master)和一系列的Datanode(workers)。Namenode負責管理HDFS的目錄樹和相關的文件元數據,Datanode則是存取文件實際內容的節點,Datanodes會定時地將block的列表彙報給Namenode。
如果Namenode出現了故障,整個HDFS集群將不可用,除非Namenode機器重啟,並且需要等待一定時間的回復初始化之後,才能正常提供服務。除此之外,Namenode還存在內存的瓶頸,當整個HDFS集群當中文件的數據達到一定的上限之後,Namenode將出現一系列與內存相關的問題。
MapReduce是Hadoop中處理海量計算的編程模型。在這種編程模型下,用戶通過定義一個map函數和一個reduce函數來解決問題。構成Map Reduce只要是JobTracker(master)和一系列的TaskTraker(workers)。
JobTracker負責管理,分配和監控所有的計算任務,TaskTraker則是實際執行任務的節點,TaskTraker會將任務的執行情況都彙報給JobTracker。
如果JobTracker出現了故障,集群中所有正在執行的計算任務都會失敗,並且在重啟JobTracker之前,無法在提交任何計算任務。
Hive是基於Hadoop的一種數據查詢工具,它可以將結構化的數據文件映射為一張資料庫表,並提供完整的SQL查詢功能,能夠將SQL語句轉換為MapReduce任務進行運行。
Cassandra是一款面向列的NoSQL資料庫,和Google的BitTable資料庫屬於同一類。此資料庫比一個類似Dynamo的Key Value資料庫功能更多,但相比面向文檔的資料庫(例如MongoDB),它所支持的查詢類型要少。
Cassandra結合了Dynamo的Key Value與Bigtable的面向列的特點:
Brisk是由DataStax開發的一款基於Apache Cassandra的開源產品,它提供了HadoopMapReduce,HDFS和Hive所包含的相關功能。Brisk中包含了一個與HDFS介面兼容的CassandraFS 。 與HDFS相比,CassandraFS沒有單點故障,整個文件系統所能承載的文件上限也不會受機器內存上限的影響。
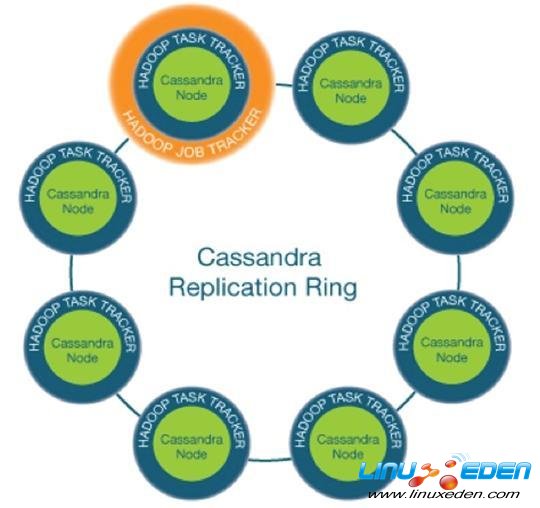
用戶如果希望使用Brisk來替代整個Hadoop系統,整個系統的部署圖如下:
整個系統只需要三類角色即可:
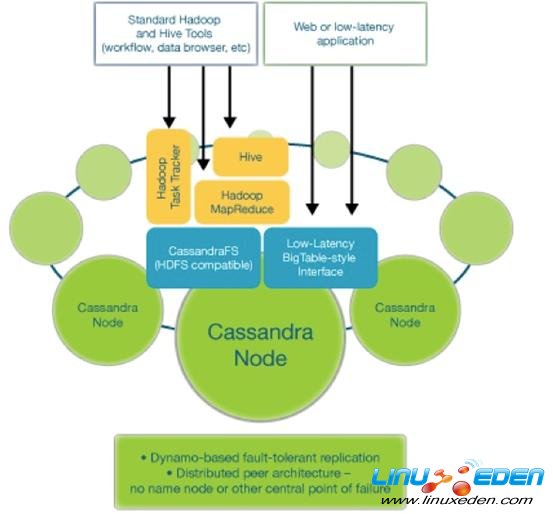
其中Cassandra Node負責實時數據讀寫和海量文件的存儲(HDFS),TaskTracker和JobTracker負責海量計算(MapReduce)。
每個模塊的功能圖示如下:
下載brisk-1.0~beta2-bin.tar.gz,jdk6並解壓。
配置環境變數
export JAVA_HOME=/home/aaron/jdk1.6.0_25 export BRISK_HOME=/home/aaron/brisk-1.0~beta2 export PATH=$JAVA_HOME/bin::$BRISK_HOME/bin:$PATH
修改Cassandra中數據存放的目錄配置參數文件:$BRISK_HOME /resources/cassandra/conf/cassandra.yaml
# directories where Cassandra should store data on disk. data_file_directories: - /var/lib/cassandra/data # commit log commitlog_directory: /var/lib/cassandra/commitlog # saved caches saved_caches_directory: /var/lib/cassandra/saved_caches
將上面的路徑修改為合適的路徑,如:
# directories where Cassandra should store data on disk. data_file_directories: - /home/aaron/brisk-1.0~beta2/resources/cassandra/data # commit log commitlog_directory: /home/aaron/brisk-1.0~beta2/resources/cassandra/commitlog # saved caches saved_caches_directory: /home/aaron/brisk-1.0~beta2/resources/cassandra/saved_caches
修改Cassandra中日誌存放的目錄配置參數文件:$BRISK_HOME/resources/cassandra/conf/log4j-server.properties
# Edit the next line to point to your logs directory
log4j.appender.R.File=/var/log/cassandra/system.log
將上面的路徑修改為合適的路徑,如:
# Edit the next line to point to your logs directory log4j.appender.R.File=/home/aaron/brisk-1.0~beta2/resources/cassandra/system.log
安裝JNA(可選)
下載jna.jar,並放到$BRISK_HOME/resources/cassandra/lib目錄中。
修改/etc/security/limits.conf,加入如下內容:
$USER soft memlockunlimited $USER hard memlock unlimited
其中$USER為實際運行Brisk的用戶名稱。
在命令行中執行如下命令即可:
briskcassandra -t
CassandraFS的使用與HDFS一致,唯一的區別在於命令行多了一個brisk的前綴。
如創建一個文件夾/test。
在HDFS中的命令為:
hadoopfs –mkdir /test在CassandraFS中執行的命令為:
briskhadoopfs –mkdir /test
本文將配置3台伺服器進行說明示例:
每台伺服器在單機部署的基礎之上,還需要修改Cassandra的配置文件resources/cassandra/conf/cassandra.yaml
cluster_name: 'BriskTest' initial_token: seed_provider: - class_name: org.apache.cassandra.locator.SimpleSeedProvider parameters: - seeds: "192.168.104.139,192.168.104.142,192.168.104.143" #每台伺服器需要填寫實際的ip地址 listen_address: 192.168.104.139
在每台伺服器的命令行中執行如下命令即可:
briskcassandra–t
在啟動之後,可以通過下面的命令查看到集群的狀態,如果所有的伺服器節點都加入到環中,並且狀態為Up,說明所有的伺服器都正常啟動了:
aaron@t01:~/brisk-1.0~beta2/resources/cassandra$ sh bin/nodetool -h 192.168.104.139 -p 7199 ring Address DC Rack Status State Load Owns Token 98783511047116141127937631965326696126 192.168.104.142 Brisk rack1 Up Normal 76.4 KB 80.25% 65174827350587778232091121501149362614 192.168.104.139 Brisk rack1 Up Normal 66.2 KB 13.78% 88615937102692658579489875256308528421 192.168.104.143 Brisk rack1 Up Normal 66.2 KB 5.98% 98783511047116141127937631965326696126
CassandraFS的實現非常精簡巧妙,是基於Cassandra0.8.1和Hadoop 0.20.203的實現,並在此之上做了簡單的擴展實現的。。
為了讓Cassandra能夠支持文件存儲的功能,Brisk在thrift介面文件($BRISK_HOME/interface/brisk.thrift)中定義了支持類似HDFS中分塊存儲文件的基本功能介面:
LocalOrRemoteBlockget_cfs_sblock( 1:required string caller_host_name, 2:required binary block_id, 3:required binary sblock_id, 4:i32 offset=0, 5:required StorageTypestorageType) throws ( 1:InvalidRequestException ire, 2:UnavailableException ue, 3:TimedOutException te, 4:NotFoundException nfe)
為了能夠實現這個介面,Brisk又修改Cassandra的啟動腳本($BRISK_HOME/resources/cassandra/bin/Cassandra)邏輯:
將默認的啟動主類:
classname="org.apache.cassandra.thrift.CassandraDaemon"
修改為:
classname="com.datastax.brisk.BriskDaemon"
新的啟動主類com.datastax.brisk.BriskDaemon在實現原有介面(cassandra.thrift)的基礎之上,而外實現了brisk.thrift中定義的get_cfs_sblock介面。
Cassadnra中定義了新的keyspace存儲文件的元數據信息和數據塊信息:
Keyspace: cfs: Replication Strategy: org.apache.cassandra.locator.NetworkTopologyStrategy Durable Writes: true Options: [Brisk:1, Cassandra:0]
其中存儲文件的元數據信息ColumnFamily的定義如下:
ColumnFamily: inode "Stores file meta data" Key Validation Class: org.apache.cassandra.db.marshal.BytesType Default column value validator: org.apache.cassandra.db.marshal.BytesType Columns sorted by: org.apache.cassandra.db.marshal.BytesType Row cache size / save period in seconds: 0.0/0 Key cache size / save period in seconds: 1000000.0/14400 Memtable thresholds: 0.103125/128/1 (millions of ops/MB/minutes) GC grace seconds: 60 Compaction min/max thresholds: 4/32 Read repair chance: 1.0 Replicate on write: false Built indexes: [inode.parent_path, inode.path, inode.sentinel] Column Metadata: Column Name: parent_path (706172656e745f70617468) Validation Class: org.apache.cassandra.db.marshal.BytesType Index Name: parent_path Index Type: KEYS Column Name: path (70617468) Validation Class: org.apache.cassandra.db.marshal.BytesType Index Name: path Index Type: KEYS Column Name: sentinel (73656e74696e656c) Validation Class: org.apache.cassandra.db.marshal.BytesType Index Name: sentinel Index Type: KEYS
其中存儲文件的數據塊信息ColumnFamily的定義如下:
ColumnFamily: sblocks "Stores blocks of information associated with a inode" Key Validation Class: org.apache.cassandra.db.marshal.BytesType Default column value validator: org.apache.cassandra.db.marshal.BytesType Columns sorted by: org.apache.cassandra.db.marshal.BytesType Row cache size / save period in seconds: 0.0/0 Key cache size / save period in seconds: 1000000.0/14400 Memtable thresholds: 0.103125/128/1 (millions of ops/MB/minutes) GC grace seconds: 60 Compaction min/max thresholds: 16/64 Read repair chance: 1.0 Replicate on write: false Built indexes: []
在Hadoop的默認配置(core-default.xml)中,定義了hdfs文件類型的實現:
<property> <name>fs.hdfs.impl</name> <value>org.apache.hadoop.hdfs.DistributedFileSystem</value> <description>The FileSystem for hdfs: uris.</description> </property>
[火星人 ] Brisk之CassandraFS已經有699次圍觀