本文首先介紹 Nutch 的背景知識,包括 Nutch 架構,爬蟲和搜索器。然後以開發一個基於 Nutch 的實際應用為例向讀者展示如何使用 Nutch 開發自己的搜索引擎。在該示例中,首先帶領讀者開發一個作為 Nutch 爬蟲抓取的目標網站,目標網站將被部署在域名為 myNutch.com 的伺服器上。然後示例說明 Nutch 爬蟲如何抓取目標網站內容,產生片斷和索引,並將結果存放在集群的2個節點上。最後使用 Nutch 檢索器提供的 API 開發應用,為用戶提供搜索介面。
簡介
Nutch 是一個基於 Java 實現的開源搜索引擎,其內部使用了高性能全文索引引擎工具 Lucene。從 nutch0.8.0開始,Nutch 完全構建在 Hadoop 分散式計算平台之上。Hadoop 除了是一個分散式文件系統外,還實現了 Google 的 GFS 和 MapReduce 演算法。因此基於 Hadoop 的 Nutch 搜索引擎可以部署在由成千上萬計算機組成的大型集群上。由於商業搜索引擎允許競價排名,這樣導致索引結果並不完全是和站點內容相關的,而 Nutch 搜索結果能夠給出一個公平的排序結果,這使得 Nutch 在垂直搜索、檔案互聯網搜索等領域得到了廣泛應用。
  |
前提條件
|
背景知識
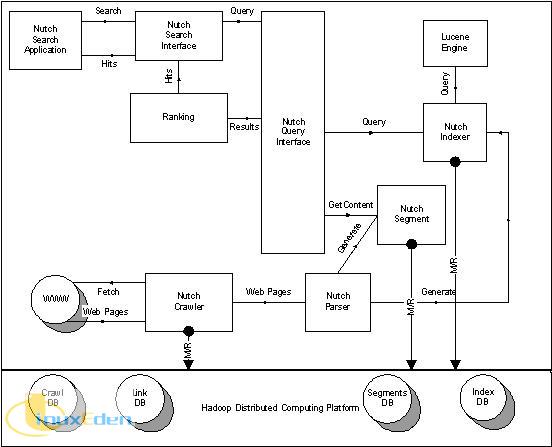
Nutch 搜索引擎是一個基於 Java 的開放源代碼的搜索引擎。Nutch 搜索引擎處理流程包括抓取流程和搜索流程,如圖 1 所示。相應地 Nutch 也分為2部分,抓取器和搜索器。在抓取流程中,抓取器也叫蜘蛛或者機器人,以廣度優先搜索(BFS)的方式從企業內部網或者互聯網抓取網頁。這個過程涉及到對 CrawlDB 和 LinkDB 資料庫的操作。然後 Nutch 解析器開始解析諸如 HTML、XML、RSS、PDF等不同格式的文檔。最後 Nutch 索引器針對解析結果建立索引並存儲到 indexDB 和 SegmentsDB 資料庫中,以供搜索器搜索使用。
在搜索流程中,搜索應用使用輸入關鍵詞調用 Nutch 搜索介面(Nutch Query Interface)。應用可通過網頁上的輸入框輸入相應關鍵詞。搜索介面解析搜索請求為 Lucene 全文檢索引擎可以識別的格式。Nutch 索引器將會調用 Lucene 引擎來響應請求在 indexDB 上展開搜索。最後搜索介面收集從索引器返回的URL、標題、錨和從 SegmentsDB 返回的內容。所有上述內容將被提供給排序演算法進行排序。排序完成後,搜索介面將返回命中的搜索結果。由於構建在 Hadoop 分散式文件系統之上, Nutch 對CrawlDB, LinkDB, SegmentsDB 和 IndexDB 資料庫的操作都是通過調用 M/R(map/reduce) 函數完成的。這使得 Nutch 具有了集群擴展能力。
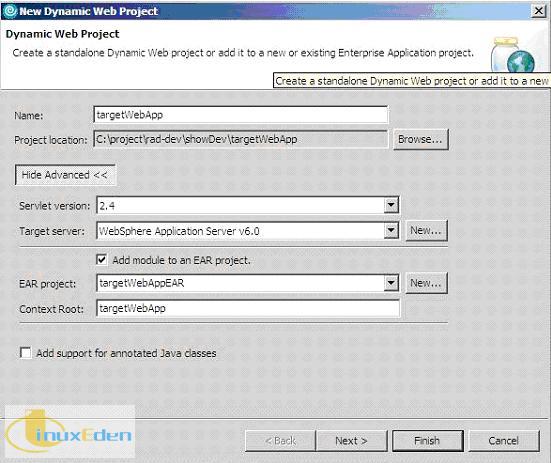
開發目標網站 targetWebSite
現在將開發一個供 Nutch 爬蟲抓取的目標網站應用。這個應用使用 RAD v6.0(Rational Application Developer)作為集成開發工具開發。應用開發完成後,將被部署在 WAS v6.0(Websphere Application Server)伺服器上,本樣例中伺服器的域名設置是 myNutch.com。讀者可以按照下面的步驟來開發該目標網站應用。
定義搜索引擎
在抓取網站之前,需要定義搜索引擎。在本樣例中Nutch被配置為集群方式。集群包括主節點(地址9.181.87.172,操作系統 RHAS3.0)和從節點(地址 9.181.87.176,操作系統 Debian)。如前文介紹,Nutch 的集群能力主要利用了 Hadoop 的分散式計算環境。下面介紹如何定義 Nutch 搜索引擎。
<property> <name>http.agent.name</name> <value>Nutch-hadoop</value> <description>HTTP 'User-Agent' request header. MUST NOT be empty - please set this to a single word uniquely related to your organization. </description> </property> <property> <name>http.agent.description</name> <value>bydenver</value> <description>Further description of our bot- this text is used in the User-Agent header. It appears in parenthesis after the agent name. </description> </property> <property> <name>http.agent.url</name> <value>myNutch.com</value> <description>A URL to advertise in the User-Agent header. This will appear in parenthesis after the agent name. Custom dictates that this should be a URL of a page explaining the purpose and behavior of this crawler. </description> </property> <property> <name>http.agent.email</name> <value>wangfp@cn.ibm.com</value> <description>An email address to advertise in the HTTP 'From' request header and User-Agent header. A good practice is to mangle this address (e.g. 'info at example dot com') to avoid spamming. </description> </property> |
<property> <name>fs.default.name</name> <value>9.181.87.172:9000</value> <description> The name of the default file system. </description> </property> <property> <name>mapred.job.tracker</name> <value>9.181.87.172:9001</value> <description> The host and port that the MapReduce job tracker runs at. </description> </property> <property> <name>mapred.map.tasks</name> <value>2</value> <description> define mapred.map tasks to be number of slave hosts </description> </property> <property> <name>mapred.reduce.tasks</name> <value>2</value> <description> define mapred.reduce tasks to be number of slave hosts </description> </property> <property> <name>dfs.name.dir</name> <value>/workspace/filesystem/name</value> </property> <property> <name>dfs.data.dir</name> <value>/workspace/filesystem/data</value> </property> <property> <name>mapred.system.dir</name> <value>/workspace/filesystem/mapreduce/system</value> </property> <property> <name>mapred.local.dir</name> <value>/workspace/filesystem/mapreduce/local</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> |
9.181.87.176 |
cd /workspace/Nutch-0.8.1 mkdir urls echo http://myNutch.com/targetWebApp > urls/urllist.txt conf/crawl-urlfilter.txt |
+^http://([a-z0-9]*\.)*myNutch.com/ |
抓取器抓取並分析
在使用 Nutch 抓取之前,首先需要啟動 Hadoop 服務。清單 6 列出了啟動 Hadoop 服務所採用的命令。隨後使用清單 7 中的命令從 myNutch.com 抓取網頁並解析,其中參數 “depth 3” 表示從網頁根路徑算起的鏈接深度;參數 “topN 10” 表示抓取器在每層需要獲取的最大頁面數目。開始抓取后,抓取器將在當前目錄下創建新目錄 crawl 作為工作目錄。
bin/hadoop dfs -put urls urls bin/hadoop dfs namenode –format |
bin/Nutch crawl urls -dir ./crawl -depth 3 -topN 10 |
對目標網站 targetWebApp 完成抓取后, 在 crawl 工作目錄下產生了五個子目錄: crawldb,linkdb,segments,indexes 和 index (見圖 6)。資料庫 crawldb 中包含頁面的數目等;linkdb 包含頁面在資料庫中的鏈接,這是抓取器真正抓取網站時由頁面的鏈接數目決定;Segments 資料庫按照時間戳分為三個片斷,每個片斷的產生都經歷了 generate/fetch/update 三個過程;Indexes 資料庫包含了在 generate/fetch/update 過程中產生的 Lucene 索引;Index 資料庫包含了經合併處理后的 Lucene 索引。

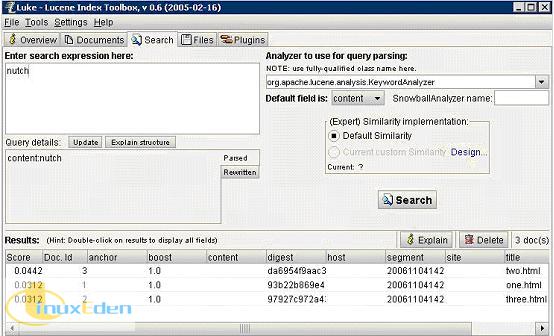
讀者也可以使用工具 Luke 去查看 Lucene 索引。 藉助 Luke,可以查看索引內容以及對索引查詢。圖 7 列出了 index 目錄下的合併后的索引。
開發搜索應用
完成抓取后,現在將開發一個基於 Nutch 搜索 API 的應用 NutchApp,提供給用戶作為搜索的介面。NutchApp 使用 Java 語言編寫,其實現首先創建 NutchConfiguration 對象,然後創建 NutchBean。這個 NutchBean 實例將用來處理用戶的搜索請求;根據請求參數,創建 query 對象,NutchBean 通過調用 search 方法來處理此 query 對象的請求。最終搜索結果以 Hits 集合。NutchApp 遍歷此 Hits 集合併列印結果到標準輸出。清單 8 列出了 NutchApp 的示例代碼。
package org.myNutch; import java.io.IOException; import java.io.*; import java.util.*; import org.apache.hadoop.conf.Configuration; import org.apache.Nutch.searcher.*; import org.apache.Nutch.util.*; public class NutchApp { /** For debugging. */ public static void main(String[] args) throws Exception { String usage = "NutchBean query"; if (args.length == 0) { System.err.println(usage); System.exit(-1); } Configuration conf = NutchConfiguration.create(); NutchBean bean = new NutchBean(conf); Query query = Query.parse(args[0], conf); Hits hits = bean.search(query, 10); System.out.println("Total hits: " + hits.getTotal()); int length = (int)Math.min(hits.getTotal(), 10); Hit[] show = hits.getHits(0, length); HitDetails[] details = bean.getDetails(show); Summary[] summaries = bean.getSummary(details, query); for ( int i = 0; i <hits.getLength();i++){ System.out.println(" "+i+" "+ details[i] + "\n" + summaries[i]); } } } |
接下來我們來運行 NutchApp。首先編譯 NutchApp.java 並打包。打包后的文件名為 NutchApp.jar。隨後在 Nutch 命令下執行。見清單 9。
Javac -cp "Nutch-0.8.1.jar;hadoop-0.4.0-patched.jar" src/org/myNutch/NutchApp.java -d lib cd lib jar cvf NutchApp.jar org/myNutch/NutchApp.class cd ../ bin/Nutch org.myNutch.NutchApp Nutch |
下面我們可以驗證我們開發的 Nutch 搜索引擎的使用效果。在搜索頁面搜索關鍵字輸入“Nutch”,NutchApp 返回的搜索結果如清單 10 所示。其中包括概要和詳細內容。
Total hits: 3 0 20061104142342/http://myNutch.com/targetWebApp/two.html ... 8 release of Nutch is now available. This is ... first release of Nutch 1 20061104142342/http://myNutch.com/targetWebApp/one.html ... 1 release of Nutch is now available. This is ... 2 20061104142342/http://myNutch.com/targetWebApp/three.html ... 2 release of Nutch is now available. This is ... |
小結
通過本文的介紹,現在你已經知道如何使用 Nutch 開發集群式的搜索引擎,並使用此搜索引擎對目標網站進行抓取和分析結果,以及如何提供搜索介面來響應用戶的搜索請求。事實上,搭建基於 Nutch 的搜索引擎是一個具有很大挑戰性的工作,因為 Nutch 本身還在不斷的發展之中,另外目標網站的結構複雜度也不盡相同。所以,針對互聯網站點文檔格式日益複雜的需求,接下來你還需要花一些精力關注 Nutch 高級特性的進展。(責任編輯:A6)
[火星人 ] 開發基於 Nutch 的集群式搜索引擎已經有853次圍觀
