這篇文章介紹了 HtmlParser 開源包和 HttpClient 開源包的使用,在此基礎上實現了一個簡易的網路爬蟲 (Crawler),來說明如何使用 HtmlParser 根據需要處理 Internet 上的網頁,以及如何使用 HttpClient 來簡化 Get 和 Post 請求操作,構建強大的網路應用程序。
使用 HttpClient 和 HtmlParser 實現簡易爬蟲
這篇文章介紹了 HtmlParser 開源包和 HttpClient 開源包的使用,在此基礎上實現了一個簡易的網路爬蟲 (Crawler),來說明如何使用 HtmlParser 根據需要處理 Internet 上的網頁,以及如何使用 HttpClient 來簡化 Get 和 Post 請求操作,構建強大的網路應用程序。
  |
HttpClient 與 HtmlParser 簡介
本小結簡單的介紹一下 HttpClinet 和 HtmlParser 兩個開源的項目,以及他們的網站和提供下載的地址。
HttpClient 簡介
HTTP 協議是現在的網際網路最重要的協議之一。除了 WEB 瀏覽器之外, WEB 服務,基於網路的應用程序以及日益增長的網路計算不斷擴展著 HTTP 協議的角色,使得越來越多的應用程序需要 HTTP 協議的支持。雖然 JAVA 類庫 .net 包提供了基本功能,來使用 HTTP 協議訪問網路資源,但是其靈活性和功能遠不能滿足很多應用程序的需要。而 Jakarta Commons HttpClient 組件尋求提供更為靈活,更加高效的 HTTP 協議支持,簡化基於 HTTP 協議的應用程序的創建。 HttpClient 提供了很多的特性,支持最新的 HTTP 標準,可以訪問這裡了解更多關於 HttpClinet 的詳細信息。目前有很多的開源項目都用到了 HttpClient 提供的 HTTP功能,登陸網址可以查看這些項目。本文中使用 HttpClinet 提供的類庫來訪問和下載 Internet上面的網頁,在後續部分會詳細介紹到其提供的兩種請求網路資源的方法: Get 請求和 Post 請求。Apatche 提供免費的 HTTPClien t源碼和 JAR 包下載,可以登陸這裡 下載最新的HttpClient 組件。筆者使用的是 HttpClient3.1。
HtmlParser 簡介
當今的 Internet 上面有數億記的網頁,越來越多應用程序將這些網頁作為分析和處理的數據對象。這些網頁多為半結構化的文本,有著大量的標籤和嵌套的結構。當我們自己開發一些處理網頁的應用程序時,會想到要開發一個單獨的網頁解析器,這一部分的工作必定需要付出相當的精力和時間。事實上,做為 JAVA 應用程序開發者, HtmlParser 為其提供了強大而靈活易用的開源類庫,大大節省了寫一個網頁解析器的開銷。 HtmlParser 是 http://sourceforge.net 上活躍的一個開源項目,它提供了線性和嵌套兩種方式來解析網頁,主要用於 html 網頁的轉換(Transformation) 以及網頁內容的抽取 (Extraction)。HtmlParser 有如下一些易於使用的特性:過濾器 (Filters),訪問者模式 (Visitors),處理自定義標籤以及易於使用的 JavaBeans。正如 HtmlParser 首頁所說:它是一個快速,健壯以及嚴格測試過的組件;以它設計的簡潔,程序運行的速度以及處理 Internet 上真實網頁的能力吸引著越來越多的開發者。 本文中就是利用HtmlParser 里提取網頁里的鏈接,實現簡易爬蟲里的關鍵部分。HtmlParser 最新的版本是HtmlParser1.6,可以登陸這裡下載其源碼、 API 參考文檔以及 JAR 包。
|
開發環境的搭建
筆者所使用的開發環境是 Eclipse Europa,此開發工具可以在 www.eclipse.org 免費的下載;JDK是1.6,你也可以在 www.java.sun.com 站點下載,並且在操作系統中配置好環境變數。在 Eclipse 中創建一個 JAVA 工程,在工程的 Build Path 中導入下載的Commons-httpClient3.1.Jar,htmllexer.jar 以及 htmlparser.jar 文件。
|
HttpClient 基本類庫使用
HttpClinet 提供了幾個類來支持 HTTP 訪問。下面我們通過一些示例代碼來熟悉和說明這些類的功能和使用。 HttpClient 提供的 HTTP 的訪問主要是通過 GetMethod 類和 PostMethod 類來實現的,他們分別對應了 HTTP Get 請求與 Http Post 請求。
GetMethod
使用 GetMethod 來訪問一個 URL 對應的網頁,需要如下一些步驟。
清單 1 的代碼展示了這些步驟,其中的註釋對代碼進行了較詳細的說明。
/* 1 生成 HttpClinet 對象並設置參數*/ HttpClient httpClient=new HttpClient(); //設置 Http 連接超時為5秒 httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000); /*2 生成 GetMethod 對象並設置參數*/ GetMethod getMethod=new GetMethod(url); //設置 get 請求超時為 5 秒 getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,5000); //設置請求重試處理,用的是默認的重試處理:請求三次 getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler()); /*3 執行 HTTP GET 請求*/ try{ int statusCode = httpClient.executeMethod(getMethod); /*4 判斷訪問的狀態碼*/ if (statusCode != HttpStatus.SC_OK) { System.err.println("Method failed: "+ getMethod.getStatusLine()); } /*5 處理 HTTP 響應內容*/ //HTTP響應頭部信息,這裡簡單列印 Header[] headers=getMethod.getResponseHeaders(); for(Header h: headers) System.out.println(h.getName()+" "+h.getValue());*/ //讀取 HTTP 響應內容,這裡簡單列印網頁內容 byte[] responseBody = getMethod.getResponseBody();//讀取為位元組數組 System.out.println(new String(responseBody)); //讀取為 InputStream,在網頁內容數據量大時候推薦使用 InputStream response = getMethod.getResponseBodyAsStream();// … } catch (HttpException e) { // 發生致命的異常,可能是協議不對或者返回的內容有問題 System.out.println("Please check your provided http address!"); e.printStackTrace(); } catch (IOException e) { // 發生網路異常 e.printStackTrace(); } finally { /*6 .釋放連接*/ getMethod.releaseConnection(); } |
這裡值得注意的幾個地方是:
在處理返回結果的時候可以根據自己的需要,進行相應的處理。如筆者是需要保存網頁
到本地,因此就可以寫一個 saveToLocaleFile(byte[] data, String filePath) 的方法,將位元組數組保存成本地文件。後續的簡易爬虫部分會有相應的介紹。
PostMethod
PostMethod 方法與 GetMethod 方法的使用步驟大體相同。但是由於 PostMethod 使用的是HTTP 的 Post 請求,因而請求參數的設置與 GetMethod 有所不同。在 GetMethod 中,請求的參數直接寫在 URL 里,一般以這樣形式出現:http://hostname:port//file?name1=value1&name2=value …。請求參數是 name,value 對。比如我想得到百度搜索“Thinking In Java”的結果網頁,就可以使 GetMethod 的構造方法中的 url 為:http://www.baidu.com/s?wd=Thinking+In+Java 。而 PostMethod 則可以模擬網頁里表單提交的過程,通過設置表單里 post 請求參數的值,來動態的獲得返回的網頁結果。清單 2 中的代碼展示了如何創建一個 Post 對象,並設置相應的請求參數。
PostMethod postMethod = new PostMethod("http://dict.cn/"); postMethod.setRequestBody(new NameValuePair[]{new NameValuePair("q","java")}); |
|
HtmlParser 基本類庫使用
HtmlParser 提供了強大的類庫來處理 Internet 上的網頁,可以實現對網頁特定內容的提取和修改。下面通過幾個例子來介紹 HtmlParser 的一些使用。這些例子其中的代碼,有部分用在了後面介紹的簡易爬蟲中。以下所有的代碼和方法都在在類 HtmlParser.Test.java 里,這是筆者編寫的一個用來測試 HtmlParser 用法的類。
網頁是一個半結構化的嵌套文本文件,有類似 XML 文件的樹形嵌套結構。使用HtmlParser 可以讓我們輕易的迭代遍歷網頁的所有節點。清單 3 展示了如何來實現這個功能。
// 循環訪問所有節點,輸出包含關鍵字的值節點 public static void extractKeyWordText(String url, String keyword) { try { //生成一個解析器對象,用網頁的 url 作為參數 Parser parser = new Parser(url); //設置網頁的編碼,這裡只是請求了一個 gb2312 編碼網頁 parser.setEncoding("gb2312"); //迭代所有節點, null 表示不使用 NodeFilter NodeList list = parser.parse(null); //從初始的節點列表跌倒所有的節點 processNodeList(list, keyword); } catch (ParserException e) { e.printStackTrace(); } } private static void processNodeList(NodeList list, String keyword) { //迭代開始 SimpleNodeIterator iterator = list.elements(); while (iterator.hasMoreNodes()) { Node node = iterator.nextNode(); //得到該節點的子節點列表 NodeList childList = node.getChildren(); //孩子節點為空,說明是值節點 if (null == childList) { //得到值節點的值 String result = node.toPlainTextString(); //若包含關鍵字,則簡單列印出來文本 if (result.indexOf(keyword) != -1) System.out.println(result); } //end if //孩子節點不為空,繼續迭代該孩子節點 else { processNodeList(childList, keyword); }//end else }//end wile } |
上面的中有兩個方法:
該方法是用類似深度優先的方法來迭代遍歷整個網頁節點,將那些包含了某個關鍵字的值節點的值列印出來。
該方法生成針對 String 類型的 url 變數代表的某個特定網頁的解析器,調用 1中的方法實現簡單的遍歷。
清單 3 的代碼展示了如何迭代所有的網頁,更多的工作可以在此基礎上展開。比如找到某個特定的網頁內部節點,其實就可以在遍歷所有的節點基礎上來判斷,看被迭代的節點是否滿足特定的需要。
NodeFilter 是一個介面,任何一個自定義的 Filter 都需要實現這個介面中的 boolean accept() 方法。如果希望迭代網頁節點的時候保留當前節點,則在節點條件滿足的情況下返回 true;否則返回 false。HtmlParse 里提供了很多實現了 NodeFilter 介面的類,下面就一些筆者所用到的,以及常用的 Filter 做一些介紹:
這些 Filter 來組合不同的 Filter,形成滿足兩個 Filter 邏輯關係結果的 Filter。
TagNameFilter:判斷節點是否具有特定的名字;NodeClassFilter:判讀節點是否是某個 HtmlParser 定義好的 Tag 類型。在 org.htmlparser.tags 包下有對應 Html標籤的各種 Tag,例如 LinkTag,ImgeTag 等。
還有其他的一些 Filter 在這裡不一一列舉了,可以在 org.htmlparser.filters 下找到。
清單 4 展示了如何使用上面提到過的一些 filter 來抽取網頁中的 <a> 標籤里的 href屬性值,<img> 標籤里的 src 屬性值,以及 <frame> 標籤里的 src 的屬性值。
// 獲取一個網頁上所有的鏈接和圖片鏈接 public static void extracLinks(String url) { try { Parser parser = new Parser(url); parser.setEncoding("gb2312"); //過濾 <frame> 標籤的 filter,用來提取 frame 標籤里的 src 屬性所、表示的鏈接 NodeFilter frameFilter = new NodeFilter() { public boolean accept(Node node) { if (node.getText().startsWith("frame src=")) { return true; } else { return false; } } }; //OrFilter 來設置過濾 <a> 標籤,<img> 標籤和 <frame> 標籤,三個標籤是 or 的關係 OrFilte rorFilter = new OrFilter(new NodeClassFilter(LinkTag.class), new NodeClassFilter(ImageTag.class)); OrFilter linkFilter = new OrFilter(orFilter, frameFilter); //得到所有經過過濾的標籤 NodeList list = parser.extractAllNodesThatMatch(linkFilter); for (int i = 0; i < list.size(); i++) { Node tag = list.elementAt(i); if (tag instanceof LinkTag)//<a> 標籤 { LinkTag link = (LinkTag) tag; String linkUrl = link.getLink();//url String text = link.getLinkText();//鏈接文字 System.out.println(linkUrl + "**********" + text); } else if (tag instanceof ImageTag)//<img> 標籤 { ImageTag image = (ImageTag) list.elementAt(i); System.out.print(image.getImageURL() + "********");//圖片地址 System.out.println(image.getText());//圖片文字 } else//<frame> 標籤 { //提取 frame 里 src 屬性的鏈接如 <frame src="test.html"/> String frame = tag.getText(); int start = frame.indexOf("src="); frame = frame.substring(start); int end = frame.indexOf(" "); if (end == -1) end = frame.indexOf(">"); frame = frame.substring(5, end - 1); System.out.println(frame); } } } catch (ParserException e) { e.printStackTrace(); } } |
如果你想要網頁中去掉所有的標籤后剩下的文本,那就是用 StringBean 吧。以下簡單的代碼可以幫你解決這樣的問題:
清單5
StringBean sb = new StringBean();
sb.setLinks(false);//設置結果中去點鏈接
sb.setURL(url);//設置你所需要濾掉網頁標籤的頁面 url
System.out.println(sb.getStrings());//列印結果
HtmlParser 提供了強大的類庫來處理網頁,由於本文旨在簡單的介紹,因此只是將與筆者後續爬虫部分有關的關鍵類庫進行了示例說明。感興趣的讀者可以專門來研究一下 HtmlParser 更為強大的類庫。
|
簡易爬蟲的實現
HttpClient 提供了便利的 HTTP 協議訪問,使得我們可以很容易的得到某個網頁的源碼並保存在本地;HtmlParser 提供了如此簡便靈巧的類庫,可以從網頁中便捷的提取出指向其他網頁的超鏈接。筆者結合這兩個開源包,構建了一個簡易的網路爬蟲。
爬蟲 (Crawler) 原理
學過數據結構的讀者都知道有向圖這種數據結構。如下圖所示,如果將網頁看成是圖中的某一個節點,而將網頁中指向其他網頁的鏈接看成是這個節點指向其他節點的邊,那麼我們很容易將整個 Internet 上的網頁建模成一個有向圖。理論上,通過遍歷演算法遍歷該圖,可以訪問到Internet 上的幾乎所有的網頁。最簡單的遍歷就是寬度優先以及深度優先。以下筆者實現的簡易爬蟲就是使用了寬度優先的爬行策略。
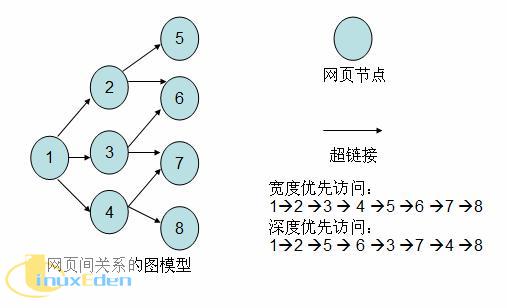
簡易爬蟲實現流程
在看簡易爬蟲的實現代碼之前,先介紹一下簡易爬蟲爬取網頁的流程。
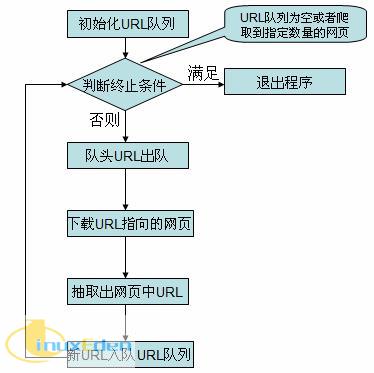
各個類的源碼以及說明
對應上面的流程圖,簡易爬蟲由下面幾個類組成,各個類職責如下:
Crawler.java:爬蟲的主方法入口所在的類,實現爬取的主要流程。
LinkDb.java:用來保存已經訪問的 url 和待爬取的 url 的類,提供url出對入隊操作。
Queue.java: 實現了一個簡單的隊列,在 LinkDb.java 中使用了此類。
FileDownloader.java:用來下載 url 所指向的網頁。
HtmlParserTool.java: 用來抽取出網頁中的鏈接。
LinkFilter.java:一個介面,實現其 accept() 方法用來對抽取的鏈接進行過濾。
下面是各個類的源碼,代碼中的註釋有比較詳細的說明。
package com.ie; import java.util.Set; public class Crawler { /* 使用種子 url 初始化 URL 隊列*/ private void initCrawlerWithSeeds(String[] seeds) { for(int i=0;i<seeds.length;i++) LinkDB.addUnvisitedUrl(seeds[i]); } /* 爬取方法*/ public void crawling(String[] seeds) { LinkFilter filter = new LinkFilter(){ //提取以 http://www.twt.edu.cn 開頭的鏈接 public boolean accept(String url) { if(url.startsWith("http://www.twt.edu.cn")) return true; else return false; } }; //初始化 URL 隊列 initCrawlerWithSeeds(seeds); //循環條件:待抓取的鏈接不空且抓取的網頁不多於 1000 while(!LinkDB.unVisitedUrlsEmpty()&&LinkDB.getVisitedUrlNum()<=1000) { //隊頭 URL 出對 String visitUrl=LinkDB.unVisitedUrlDeQueue(); if(visitUrl==null) continue; FileDownLoader downLoader=new FileDownLoader(); //下載網頁 downLoader.downloadFile(visitUrl); //該 url 放入到已訪問的 URL 中 LinkDB.addVisitedUrl(visitUrl); //提取出下載網頁中的 URL Set<String> links=HtmlParserTool.extracLinks(visitUrl,filter); //新的未訪問的 URL 入隊 for(String link:links) { LinkDB.addUnvisitedUrl(link); } } } //main 方法入口 public static void main(String[]args) { Crawler crawler = new Crawler(); crawler.crawling(new String[]{"http://www.twt.edu.cn"}); } } |
package com.ie; import java.util.HashSet; import java.util.Set; /** * 用來保存已經訪問過 Url 和待訪問的 Url 的類 */ public class LinkDB { //已訪問的 url 集合 private static Set<String> visitedUrl = new HashSet<String>(); //待訪問的 url 集合 private static Queue<String> unVisitedUrl = new Queue<String>(); public static Queue<String> getUnVisitedUrl() { return unVisitedUrl; } public static void addVisitedUrl(String url) { visitedUrl.add(url); } public static void removeVisitedUrl(String url) { visitedUrl.remove(url); } public static String unVisitedUrlDeQueue() { return unVisitedUrl.deQueue(); } // 保證每個 url 只被訪問一次 public static void addUnvisitedUrl(String url) { if (url != null && !url.trim().equals("") && !visitedUrl.contains(url) && !unVisitedUrl.contians(url)) unVisitedUrl.enQueue(url); } public static int getVisitedUrlNum() { return visitedUrl.size(); } public static boolean unVisitedUrlsEmpty() { return unVisitedUrl.empty(); } } |
package com.ie; import java.util.LinkedList; /** * 數據結構隊列 */ public class Queue<T> { private LinkedList<T> queue=new LinkedList<T>(); public void enQueue(T t) { queue.addLast(t); } public T deQueue() { return queue.removeFirst(); } public boolean isQueueEmpty() { return queue.isEmpty(); } public boolean contians(T t) { return queue.contains(t); } public boolean empty() { return queue.isEmpty(); } } |
package com.ie; import java.io.DataOutputStream; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler; import org.apache.commons.httpclient.HttpClient; import org.apache.commons.httpclient.HttpException; import org.apache.commons.httpclient.HttpStatus; import org.apache.commons.httpclient.methods.GetMethod; import org.apache.commons.httpclient.params.HttpMethodParams; public class FileDownLoader { /**根據 url 和網頁類型生成需要保存的網頁的文件名 *去除掉 url 中非文件名字元 */ public String getFileNameByUrl(String url,String contentType) { url=url.substring(7);//remove http:// if(contentType.indexOf("html")!=-1)//text/html { url= url.replaceAll("[\\?/:*|<>\"]", "_")+".html"; return url; } else//如application/pdf { return url.replaceAll("[\\?/:*|<>\"]", "_")+"."+ \ contentType.substring(contentType.lastIndexOf("/")+1); } } /**保存網頁位元組數組到本地文件 * filePath 為要保存的文件的相對地址 */ private void saveToLocal(byte[] data,String filePath) { try { DataOutputStream out=new DataOutputStream( new FileOutputStream(new File(filePath))); for(int i=0;i<data.length;i++) out.write(data[i]); out.flush(); out.close(); } catch (IOException e) { e.printStackTrace(); } } /*下載 url 指向的網頁*/ public String downloadFile(String url) { String filePath=null; /* 1.生成 HttpClinet 對象並設置參數*/ HttpClient httpClient=new HttpClient(); //設置 Http 連接超時 5s httpClient.getHttpConnectionManager().getParams(). setConnectionTimeout(5000); /*2.生成 GetMethod 對象並設置參數*/ GetMethod getMethod=new GetMethod(url); //設置 get 請求超時 5s getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT,5000); //設置請求重試處理 getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler()); /*3.執行 HTTP GET 請求*/ try{ int statusCode = httpClient.executeMethod(getMethod); //判斷訪問的狀態碼 if (statusCode != HttpStatus.SC_OK) { System.err.println("Method failed: "+ getMethod.getStatusLine()); filePath=null; } /*4.處理 HTTP 響應內容*/ byte[] responseBody = getMethod.getResponseBody();//讀取為位元組數組 //根據網頁 url 生成保存時的文件名 filePath="temp\\"+getFileNameByUrl(url, getMethod.getResponseHeader("Content-Type").getValue()); saveToLocal(responseBody,filePath); } catch (HttpException e) { // 發生致命的異常,可能是協議不對或者返回的內容有問題 System.out.println("Please check your provided http address!"); e.printStackTrace(); } catch (IOException e) { // 發生網路異常 e.printStackTrace(); } finally { // 釋放連接 getMethod.releaseConnection(); } return filePath; } //測試的 main 方法 public static void main(String[]args) { FileDownLoader downLoader = new FileDownLoader(); downLoader.downloadFile("http://www.twt.edu.cn"); } } |
package com.ie; import java.util.HashSet; import java.util.Set; import org.htmlparser.Node; import org.htmlparser.NodeFilter; import org.htmlparser.Parser; import org.htmlparser.filters.NodeClassFilter; import org.htmlparser.filters.OrFilter; import org.htmlparser.tags.LinkTag; import org.htmlparser.util.NodeList; import org.htmlparser.util.ParserException; public class HtmlParserTool { // 獲取一個網站上的鏈接,filter 用來過濾鏈接 public static Set<String> extracLinks(String url,LinkFilter filter) { Set<String> links = new HashSet<String>(); try { Parser parser = new Parser(url); parser.setEncoding("gb2312"); // 過濾 <frame >標籤的 filter,用來提取 frame 標籤里的 src 屬性所表示的鏈接 NodeFilter frameFilter = new NodeFilter() { public boolean accept(Node node) { if (node.getText().startsWith("frame src=")) { return true; } else { return false; } } }; // OrFilter 來設置過濾 <a> 標籤,和 <frame> 標籤 OrFilter linkFilter = new OrFilter(new NodeClassFilter( LinkTag.class), frameFilter); // 得到所有經過過濾的標籤 NodeList list = parser.extractAllNodesThatMatch(linkFilter); for (int i = 0; i < list.size(); i++) { Node tag = list.elementAt(i); if (tag instanceof LinkTag)// <a> 標籤 { LinkTag link = (LinkTag) tag; String linkUrl = link.getLink();// url if(filter.accept(linkUrl)) links.add(linkUrl); } else// <frame> 標籤 { // 提取 frame 里 src 屬性的鏈接如 <frame src="test.html"/> String frame = tag.getText(); int start = frame.indexOf("src="); frame = frame.substring(start); int end = frame.indexOf(" "); if (end == -1) end = frame.indexOf(">"); String frameUrl = frame.substring(5, end - 1); if(filter.accept(frameUrl)) links.add(frameUrl); } } } catch (ParserException e) { e.printStackTrace(); } return links; } //測試的 main 方法 public static void main(String[]args) { Set<String> links = HtmlParserTool.extracLinks( "http://www.twt.edu.cn",new LinkFilter() { //提取以 http://www.twt.edu.cn 開頭的鏈接 public boolean accept(String url) { if(url.startsWith("http://www.twt.edu.cn")) return true; else return false; } }); for(String link : links) System.out.println(link); } } 清單11 LinkFilter.java package com.ie; public interface LinkFilter { public boolean accept(String url); } |
這些代碼中關鍵的部分都在 HttpClient 和 HtmlParser 介紹中說明過了,其他部分也比較容易,請感興趣的讀者自行理解。
|
總結
這篇文章主要是介紹與展示了如何使用開源的 HttpClinet 包和 HtmlParser 包,以及結合這兩者來給出了一個簡易網路爬蟲程序的實現,當然這個爬蟲與實際真正的爬蟲還是有所差距。由於更多的目的是關注這兩個開源包的運用,加上本文篇幅有限,因此,沒有對這兩個開源包做非常詳盡的介紹。希望這篇文章能夠引導讀者對 HttpClient 包和 HtmlParser 產生興趣,從而利用他們構建強大的 JAVA 網路應用程序。 (責任編輯:A6)
[火星人 ] 使用 HttpClient 和 HtmlParser 實現簡易爬蟲已經有956次圍觀
