毫無疑問,HTML、HTTP 和 XML 是支撐 Web 技術的三種最重要的技術。對於 PHP 開發人員而言,使用這些技術可能比較麻煩。但是,新的 QueryPath 庫,即 jQuery JavaScript 庫面向 PHP 的一個版本,為使用 XML、HTML 和 HTTP 提供了一個方便的 API。從 Web 頁面到 Web 服務、從 SVG 到 SPARQL、從 RDF 到 Atom,QueryPath 為目前使用 PHP 的 Web 開發提供了一個健壯而簡單的 API。在本文中,學習構建 QueryPath 對象,以及如何遍歷和操縱 XML 和 HTML。另外考察一個使用 QueryPath 訪問 Web 服務(Twitter)的例子。
簡介
可以說,在過去 15 年的時間裡,對 Web 的爆炸式增長貢獻最大的三大技術是 HTML、HTTP 和 XML。 您也許會將這三種技術加以擴展,指出還有 CSS、 JavaScript 等類似的技術。但這 “三大技術” 的地位仍然是無可撼動的。
PHP 也曾在 Web 開發領域造成轟動。由於易於開發和以 Web 為中心的模型,PHP 使 Web 站點從小小的主頁變成像 Yahoo! 這樣強大的站點。但是,通過 PHP 來使用這三種技術 — 尤其是 XML — 有時候會比較複雜。在本文中,了解 QueryPath,這是一個 PHP 庫,它在設計時考慮了兩個目標:
本文探索如何構建 QueryPath 對象、遍歷 XML 和 HTML、操縱 XML 和 HTML 以及使用 QueryPath 訪問 Web 服務(使用 Twitter 作為示例服務)。
下一節簡要介紹這個庫和它的設計。
  |
QueryPath
為了提供簡單性,QueryPath 使用一種簡潔的語法。方法名稱簡短地表示出它們所做的事情(例如,text()、append()、 remove())。由於大多數方法返回一個 QueryPath 對象,因此方法調用是可鏈接的(chainable),也就是說,可以在一個語句中依次調用多個方法。 這一慣例有時被稱作連續介面(fluent interface)。為了讓 JavaScript 開發人員感到熟悉,QueryPath 實現了大部分的 jQuery 遍歷和操縱函數和行為。
為了具有健壯性,QueryPath 提供了為解決裝載、搜索、讀寫 XML 和 HTML 內容等典型用例而設計的工具。但是,無論庫有多大,一種通用的 API 無法滿足所有的要求。為解決這個問題,QueryPath 提供一種擴展機制,以便為 QueryPath 添加新的方法。QueryPath 還包括用於添加資料庫支持、模板支持和附加的 XML 特性的擴展。
您也許有疑問:“為什麼還是 XML 或 HTML 工具?PHP V5 已經有一些 XML 工具,包括一個 Document Object Model(DOM)實現和 SimpleXML 庫。為什麼還有增加一個?”答案很簡單:QueryPath 被設計為一種通用的工具。而 DOM API 比較複雜和麻煩。它的面向對象模型也許很強大,但即使最簡單的任務都需要編寫很多行代碼。另一方面,SimpleXML 對於很多編程任務而言又過於簡單。除非 XML 是完全可預測的,否則導航一個 SimpleXML 文檔絕不簡單。
QueryPath 試圖在 DOM 的豐富性與 SimpleXML 的簡單性之間找到一個最佳結合點。
需求
QueryPath 是一個純 PHP 庫。要使用它,只需從官方 Web 站點 下載 它,並將它添加到 PHP 庫路徑中。
QueryPath 對系統的要求很低。只要啟用 DOM 擴展,它就可以在 PHP V5 上工作。PHP V5 的大多數發行版都可以滿足這個需求。QueryPath 不支持早已被棄用的 PHP V4。
|
剖析 QueryPath 鏈
對於 QueryPath 的典型使用,有四個最重要的概念:
清單 1 中的代碼展示了所有這些要點。
<?php require 'QueryPath/QueryPath.php'; qp('sample.html')->find('title')->text('Hello World')->writeHTML(); ?> |
以上例子需要一個庫,即 QueryPath/QueryPath.php。除非還要裝載 QueryPath 擴展,否者只需包括這個庫就可以使用 QueryPath。
|
|
例子中接下來一行代碼是一個 QueryPath 鏈,它做以下事情。
在一個有效的 HTML 文檔中,該搜索只能在文檔的頭部找到一個匹配的 <title/> 元素。
以上例子實際上還可以縮短一點,因為 qp() 工廠函數帶有一個 CSS 選擇器作為可選的第二個參數。清單 2 顯示了縮短后的版本。
<?php require 'QueryPath/QueryPath.php'; qp('sample.html', 'title')->text('Hello World')->writeHTML(); ?> |
假設 sample.html 是一個最基本的 HTML 文檔,以上代碼(清單 1 或清單 2)的結果看上去將如清單 3 所示。加粗的行包含我們設置的標題。
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html lang="en"> <head> <title>Hello World</title> </head> <body> </body> </html> |
這些簡單的例子展示了 QueryPath 可以執行的一些常見的任務。接下來幾個小節探索一些方法。然後,您將把這些構建塊裝配起來,創建一個簡單的 Web 服務客戶機。
|
qp() 工廠函數
QueryPath 庫中最常用的函數是 qp() 工廠函數。實際上,它執行創建新的 QueryPath 對象的任務。它被用於傳統的構造函數。
如果您熟悉面向對象設計模式,那麼可能會意識到 qp() 是工廠模式的一個變種。 QueryPath 不是用構造器方法定義一個工廠類,而是使用一個函數。這種方法除了可以節省鍵盤輸入外(在鏈接方法時比較重要),還可以使 QueryPath 更貼近 jQuery,減少 jQuery 熟悉者的學習曲線。
一個 QueryPath 對象與一個 XML 或 HTML 文檔相關聯。當構造 QueryPath 對象時,文檔被綁定到該對象。qp() 函數帶有 3 個參數,這 3 個參數都是可選的:
|
|
qp() 支持將很多類型的數據作為第一個參數,從而方便構建 QueryPath 對象。QueryPath 可以以一個文件名或 URL 開始,然後裝載一個文檔。如果傳遞的是一個 XML 或 HTML 字元串,QueryPath 將解析該內容。當然,它可以接受另外兩種常用的 XML 文檔的對象表示:DOM 和 SimpleXML。清單 4 展示 qp() 函數如何解析包含 XML 的字元串。
<?php require 'QueryPath/QueryPath.php'; $xml = '<?xml version="1.0"?><doc><item/></doc>'; $qp = qp($xml); ?> |
當清單 4 中的代碼運行時, $qp 將引用一個 QueryPath 對象,該對象在內部指向 XML 解析后的表示。前面的例子傳入的是一個文件名。如果 PHP 被配置為允許 HTTP/HTTPS 流包裝器(在大多數 PHP V5 發行版中是標準配置),那麼甚至可以裝載遠程 HTTP URL,如下所示。
<?php require 'QueryPath/QueryPath.php'; $qp = qp('http://example.com/file.xml'); ?> |
這樣便可以使用 QueryPath 訪問 Web 服務。(可以使用第 3 個參數 qp() 傳遞流上下文,以便對連接設置進行調整)。當創建新文檔時,有一個添加樣板 HTML 的快捷方式,如下所示。
<?php require 'QueryPath/QueryPath.php'; $qp = qp(QueryPath::HTML_STUB); ?> |
QueryPath::HTML_STUB 常量定義一個基本的 HTML 文檔,如下所示。
<?xml version="1.0"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"/> <title>Untitled</title> </head> <body></body> </html> |
以這個框架文檔為基礎,可以更快地生成 HTML。
至此,您知道了如何創建新的指向文檔的 QueryPath 對象,並且看到了一個簡單的 CSS 選擇器。下一小節討論如何使用 QueryPath 遍歷文檔。
遍歷文檔
打開文檔后,需要在文檔中查找感興趣的內容。QueryPath 的設計使得這一任務變得很容易。為了簡化遍歷需求,QueryPath 提供了一些用於遍歷的方法。大多數方法使用 CSS3 選擇器查找所需的節點。
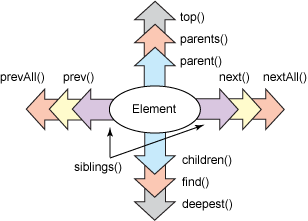
圖 1 總結了常用的遍歷函數。下面一一描述每個函數。雖然還有一些遍歷函數沒有提到,但這裡覆蓋了大多數常見的需求。
| 方法 | 描述 | 是否帶 CSS 選擇器 |
|---|---|---|
| find() | 選擇與選擇器匹配的任何元素(在當前選擇的節點下) | 是 |
| xpath() | 選擇與給定 XPath 查詢匹配的元素 | 否(使用 XPath 查詢) |
| top() | 選擇文檔元素(根元素) | 否 |
| parents() | 選擇任何祖先元素 | 是 |
| parent() | 選擇直接父元素 | 是 |
| siblings() | 選擇所有同胞(sibling)元素(包括之前和之後的元素) | 是 |
| next() | 選擇后一個同胞元素 | 是 |
| nextAll() | 選擇當前元素之後的所有同胞元素 | 是 |
| prev() | 選擇前一個同胞元素 | 是 |
| prevAll() | 選擇當前元素之前的所有同胞元素 | 是 |
| children() | 選擇當前元素的直接子元素 | 是 |
| deepest() | 選擇當前元素下最深的節點 | 否 |
QueryPath 中的很多方法可以以查詢作為參數,進一步指定應該選擇什麼項。如表 1 中第三列所示,幾乎所有這些方法都帶有一個作為可選參數的 CSS3 選擇器。(xpath() 函數則帶有一個 XPath 查詢,而不是 CSS3 選擇器)。只有 top() 和 deepest() 不使用查詢作為參數。
可以通過另一個簡單的例子了解如何進行遍歷。假設有一個像下面這樣的 XML 文檔。
<?xml version="1.0"?> <root> <child id="one"/> <child id="two"/> <child id="three"/> <ignore/> </root> |
<root/> 元素有 4 個子元素:其中有 3 個名為 <child/>,還有一個名為 <ignore/>。可以用一個 QueryPath 查詢選擇 <root/> 的所有 4 個子元素。
<?php require 'QueryPath/QueryPath.php'; $xml = '<?xml version="1.0"?> <root> <child id="one"/> <child id="two"/> <child id="three"/> <ignore/> </root>'; $qp = qp($xml, 'root')->children(); print $qp->size(); ?> |
children() 方法將選擇 <root/> 元素的所有直接子元素。最後一行列印 QueryPath 對象中匹配項的數量,最終列印的結果為 4。
假設只需選擇 3 個 <child/> 元素,而不需要選擇 <ignore/> 元素。 清單 10 顯示了如何實現這一點。
<?php require 'QueryPath/QueryPath.php'; $xml = '<?xml version="1.0"?> <root> <child id="one"/> <child id="two"/> <child id="three"/> <ignore/> </root>'; $qp = qp($xml, 'root')->children('child'); print $qp->size(); ?> |
最後的 print 語句將列印 QueryPath 當前選擇的項的數量。它將返回 3。在內部,QueryPath 跟蹤這 3 個元素。它們被存儲為當前上下文。如果執行進一步的查詢,那麼查詢將從這 3 個元素開始。如果試圖附加數據,那麼數據將被附加到這 3 個元素后。
CSS 選擇器
|
|
CSS 選擇器是 CSS 語句的一部分,用於選擇將應用某種樣式的元素。CSS 選擇器還可以在樣式表上下文之外使用。QueryPath 使用選擇器作為查詢語言,並支持 CSS3 選擇器 標準 中描述的特性集。
CSS 選擇器在 QueryPath 中扮演很重要的角色。您已經看到,有 10 個函數使用 CSS 選擇器作為參數。到目前為止使用的選擇器是簡單的標記名查詢。CSS3 選擇器要比前面的例子強大得多。對 CSS3 選擇器的詳細描述超出了本文的範圍,但表 2 提供了一些常見的選擇器模式的例子。
| 選擇器模式 | 描述 | 示例匹配項 |
|---|---|---|
| p | 找到標記名為 <p/> 的元素 | <p> |
| .container | 找到 class 屬性被設為 container 的元素 | <div class="container"/> |
| #menu | 找到 id 屬性被設為 menu 的元素。基於 ID 的搜索以這種方式進行 | <div id="menu"/> |
| [type="inline"] | 找到 type 屬性的值為 inline 的元素 | <code type="inline"/> |
| tr > th | 找到直接父元素為 <tr> 的 <th> 元素 | <tr><th/></tr> |
| table td | 找到祖先(例如父親或祖父)中有 <table> 元素的 <td> 元素 | <table><tr><td/></tr></table> |
| li:first | 獲取第一個名為 <li/> 的元素。支持的偽類包括 :last、 :even 和 :odd | <li/> |
| RDF|seq | 找到 <RDF:seq> 元素。 QueryPath 包括用於 XML 名稱空間的 CSS3 選擇器。名稱空間支持延伸到屬性和元素 | <RDF:seq> |
這些常見的選擇器模式可以加以組合,形成複雜的選擇器,例如
div.content ul>li:first |
迭代匹配項
您了解了遍歷文檔的兩個方面:QueryPath 提供的方法和 CSS3 選擇器支持。第三個方面是迭代選擇的項。
QueryPath 對象是可遍歷的(traversable)。在 PHP 中,這意味著對象可以當做迭代器。標準的 PHP 循環結構可以遍歷 QueryPath 對象選擇的元素。還記得嗎,清單 10 中的例子是一個簡單的查詢,它從一個 XML 文檔中檢索 3 個元素。接下來的例子將以這個例子為基礎。
如果要單獨處理每個項,應該怎麼辦?很容易,因為 QueryPath 可以用作迭代器。清單 11 顯示了一個例子。
<?php require 'QueryPath/QueryPath.php'; $xml = '<?xml version="1.0"?> <root> <child id="one"/> <child id="two"/> <child id="three"/> <ignore/> </root>'; $qp = qp($xml, 'root')->children('child'); foreach ($qp as $child) { print $child->attr('id') . PHP_EOL; } ?> |
當 foreach 循環迭代時,它將每個匹配項賦給 $child 變數。但是,$child 不是真正的元素,它是指向當前元素的一個 QueryPath 對象。您可以任意使用所有常見的 QueryPath 方法。
為了使 API 與 jQuery 的 API 類似, QueryPath 提供一些可同時作為 accessor 和 mutator — 或 getter 和 setter 的方法。取決於參數,同一個方法可以檢索(access)數據,或者更改(mutate)數據。 attr() 函數就是一個例子。 qp()->attr('name') 檢索 name 屬性的值。 qp()->attr('name', 'value') 將 name 屬性的值設為 value。還有一些方法,包括 text()、html() 和 xml(),作為 accessor 和 mutator 同時執行兩種任務。
由於每個迭代的項包裝在一個 QueryPath 對象中,所以可以通過 $child 任意使用所有標準的 QueryPath 方法。上面的例子使用了 attr() 函數,這是一個元素中的屬性的 accessor 和 mutator。
attr() 方法檢索名為 id 的屬性的值。下面顯示以上代碼的輸出。
one two three |
您已經了解了如何使用 QueryPath 方法、CSS3 選擇器和迭代技術遍歷文檔。下一節探索如何用 QueryPath 修改文檔。
|
操縱文檔
除了使用 QueryPath 搜索文檔外,還可以使用它添加、修改和移除文檔中的數據。在清單 1 中可以大致了解 QueryPath 的功能。為了方便,下面再重複一遍。
<?php require 'QueryPath/QueryPath.php'; qp('sample.html')->find('title')->text('Hello World')->writeHTML(); ?> |
在這個例子中,text() 函數用於修改 <title/> 元素的內容。QueryPath 提供了十幾個用於更改文檔的方法。圖 2 展示一些常用的修改方法如何工作。這些方法都是添加或替換數據。綠色的標記表示當前被選中的元素。
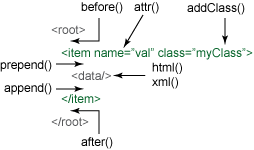
每個方法以字元串數據(通常是以 HTML 或 XML 片段的形式)作為參數,並將數據插入到文檔中。隨後立即可以訪問和進一步操縱新插入的數據。
使用 HTML 和 XML 片段
實際上有兩類方法。第一類方法使用任意的 XML 片段,如下所示。
| append() | 將數據添加為當前選中元素的最後一個 子元素 |
| prepend() | 將數據添加為當前選中元素的第一個 子元素 |
| after() | 將數據直接插在當前選中元素之後 |
| before() | 將數據直接插在當前選擇的元素之前 |
| html() | 替換 HTML 文檔中當前元素的子內容 |
| xml() | 替換 XML 文檔中當前元素的子內容 |
以上方法需要一個參數,該參數包含一個格式良好的 XML 或 HTML 數據的字元串。清單 14 有一個使用 html() 方法的例子。
<?php require 'QueryPath/QueryPath.php'; qp($file)->find('div.content')->html('<ul><li>One</li></ul>'); ?> |
圖 2 中沒有給出 remove() 方法(難以清楚地表示移除)。 remove() 方法移除文檔中的元素。如果不帶參數調用,該方法將移除當前選中的元素。但是,和很多其他的 QueryPath 方法一樣, remove() 可以使用一個 CSS3 選擇器作為可選參數。如果提供了一個選擇器,那麼只移除與選擇器匹配的項。
使用屬性
圖 2 中的第二類方法則操縱元素中的屬性。下面介紹兩個這樣的例子。
| attr() | 獲取或設置每個選中的元素上給定屬性的值 |
| addClass() | 為當前選中的每個元素添加一個類 |
還有其他一些與屬性相關的方法。例如 removeClass() 方法,該方法以一個類名作為參數,它將移除元素中的一個類。 removeAttr() 以一個屬性名作為參數,它將從所有當前選中的元素中移除具有該名稱的屬性。
現在可以將所有這些基本功能組合到一起,形成有趣的東西。
|
示例:用 QueryPath 搜索 Twitter
Twitter 是一個流行的微博客服務,通過它可以發布短消息,同時還可以跟隨其他 Twitter 用戶的微博客。 Twitter 提供了一個簡單的 Web 服務,用於公布該平台的很多特性。
下面的例子使用 QueryPath 在 Twitter 伺服器上執行搜索,並以 HTML 格式列印結果。可以將一個工具添加到已有的 Web 站點,以顯示最近的關於一個感興趣的話題的 Twitter 活動。
Twitter 的搜索伺服器偵聽一個標準的 HTTP 伺服器,當被請求時,以 Atom XML 格式返回搜索結果。我們的例子將搜索最近 5 個提到 QueryPath 的貼子。為了運行這種搜索,並以 Atom 格式返回內容,只需在 URL 中編寫必要的信息: http://search.twitter.com/search.atom?rpp=5&q=QueryPath。
加粗的 3 個部分表示針對這個應用程序進行了調整的參數。
| .atom | 提供這個擴展名是為了告訴伺服器需要返回 Atom XML 內容 |
| rpp=5 | RPP 指定每頁顯示的結果數。我們想要返回 5 條結果。默認情況下,將返回 5 條最近的結果 |
| q=QueryPath | 這是查詢。Twitter 支持更複雜的搜索查詢,但對於這個簡單的例子只需要這樣的查詢。 |
當裝載這個 URL 時,Twitter 將返回一個 Atom 格式的 XML 文檔。下面的清單 15 顯示一個經過大量簡化的返迴文檔。這裡只顯示最關心的信息(只顯示一個條目)。
<?xml version="1.0" encoding="UTF-8"?> <feed> <entry> <content type="html"> Last night I added XSD schema validation and XSL Transformation (XSLT) support to <b>QueryPath</b> (as extensions). Will commit them today. </content> <link type="image/png" rel="image" href="http://example.com/img.jpg"/> <author> <name>technosophos (M Butcher)</name> <uri>http://twitter.com/technosophos</uri> </author> </entry> </feed> |
清單 16 顯示了執行搜索的簡要的 QueryPath 代碼,處理返回的 XML,並創建一個文檔。
<?php require 'QueryPath/QueryPath.php'; $url = 'http://search.twitter.com/search.atom?rpp=5&q=QueryPath'; $out = qp(QueryPath::HTML_STUB, 'body')->append('<ul/>')->find('ul'); foreach (qp($url, 'entry') as $result) { $title = $result->children('content')->text(); $img = $result->siblings('link[rel="image"]')->attr('href'); $author = $result->parent()->find('author>name')->text(); $out->append("<li><img src='$img'/> <em>$author</em><br/>$title</li>"); } $out->writeHTML(); ?> |
如果使用 Web 瀏覽器執行以上代碼,可以看到圖 3 所示的結果。
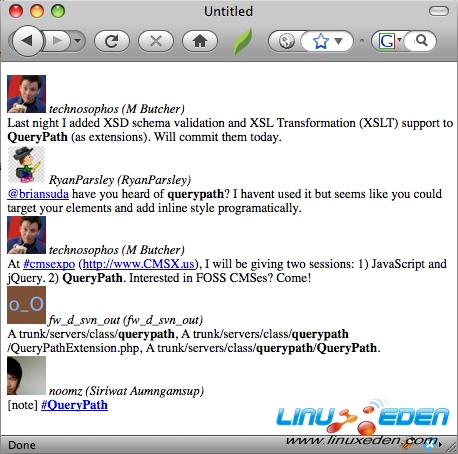
清單 16 中的代碼有 14 行,其中只有 9 行代碼做實際的工作。以上代碼是如何產生圖 3 中的視圖的呢?
$url 變數存放前面提到的 Twitter URL。$out 變數指向用於將 HTML 寫到客戶機的 QueryPath 對象。 從一個基本的文檔 (QueryPath::HTML_STUB)開始,添加一個無序列表,並(使用 find())選擇這個新列表。
foreach 循環是腳本中最重要的一行: foreach (qp($url, 'entry') as $result)。這裡創建一個新的 QueryPath 對象。由於傳遞了一個 URL,QueryPath 將檢索遠程 Atom 文檔,並解析結果。另外,由於傳遞了選擇器 entry,QueryPath 將選擇文檔中的所有條目。回頭查看一下 清單 15,看看這是文檔中的哪個部分。返回的文檔中將有 5 個條目(因為 URL 中這樣設置了 rpp 標誌)。這 5 個條目中的每個條目看上去都應該與清單 15 中的 <entry/> 類似。
循環獲取了 3 個數據部分:
| $title | 條目的內容 |
| $img | 發帖用戶的頭像的 URL |
| $author | 發帖用戶的用戶名 |
為了獲取每塊數據,可以使用不同的 QueryPath 方法。例如,可以使用 $result->children('content')->text(); 獲得 $title。
|
|
循環中首先選擇標記名為 content 的所有子元素,然後從發現的節點中獲得 CDATA 文本。每個條目將有一個 <content/> 元素。
現在需要獲得圖像 URL。在前面的鏈中,選擇了 <content/> 元素,所以這就是起點。現在需要搜索 <content/> 的同胞,找到形如 <link rel="image"/> 的元素。 為此,使用 siblings() 函數,並提供一個選擇器作為參數。然後使用 attr() 函數獲得元素的 href 屬性的值。
最後,從 <link/> 元素跳回到它的父元素,接著使用 find('author>name'),獲得作者的用戶名。(請查看 表 2)。在這裡,可以使用 text() 獲得作者的用戶名的文本。
在 foreach 循環的每次迭代的最後,構建一個 HTML 片段,並使用 append() 將這個片段插入到 $out QueryPath 中。
迭代完從 Twitter 返回的結果后,可以在腳本的最後將 HTML 文檔寫到瀏覽器:$out->writeHTML();。
這樣就完成了。在大約十幾行代碼中,您完成了與一個遠程服務的交互。可以通過這種方式,使用 QueryPath 訪問任何使用 HTTP 和 XML 或 HTML 的 Web 服務。QueryPath 附帶的例子展示了如何設置連接參數、對 SPARQL 端點執行 SPARQL 查詢以及解析複雜的、多名稱空間的文檔。QueryPath 為使用 Web 服務帶來巨大的潛力。
|
結束語
在本文中,您探索了 QueryPath 庫的基礎。您學習了如何創建 QueryPath 對象、遍歷文檔和操縱內容。您還構建了一個小型的例子腳本,該腳本使用流行的 Twitter 微博客服務的 Web 服務 API。
本文只是初步發掘 QueryPath 庫的一些可能的應用。例如,本文只提到資料庫 API,可使用該 API 將 RDBMS 支持集成到 QueryPath。想象一下,運行一個 SQL SELECT 語句,並將結果直接合併到一個符合自己的規範的 HTML 表格中。或者再想象一下,構建一個 XML 導入器,用於解析數據並將數據直接插入到資料庫中。
QueryPath 還有一些特性這裡沒有提到。通過映射器和過濾器,可以讓 QueryPath 運行定製的函數來轉換或過濾 QueryPath 數據。通過 QPTPL 擴展,可以將數據插入到預定義的純 HTML 模板中。QueryPath 還支持用戶定義的擴展。通過編寫一個簡單的類定義,可以將自己的方法添加到 QueryPath 中。(責任編輯:A6)
[火星人 ] 了解 QueryPath PHP 庫 ——快捷、簡便地使用 XML 和 HTML已經有1078次圍觀
