綜合利用Nagios、Ganglia和Splunk搭建起的雲計算平台監控體系,具備錯誤報警、性能調優、問題追蹤和自動生成運維報表的功能。有了這套系統,就可輕鬆管理Hadoop/HBase雲計算平台。
雲計算早已不是停留在概念階段了,各大公司都購買了大量的機器,開始正式的部署和運營。而動輒上百台的性能強勁的伺服器,為運營管理帶來了巨大的挑戰。
如果沒有方便的監控報警平台,對於管理員而言猶如噩夢,每天都將如救火隊員一樣,飛快地敲擊鍵盤,用原始的Unix命令在多台機器中疲於奔命。
如果沒有好的日誌管理平台,對於開發者Troubleshooting更是一件淚流滿面的事情。
而如果你是運維團隊的總負責人,簡潔清晰的Report則非常重要。Stakeholder們動不動就可能問起系統的SLA、機器的利用率等諸多問題,畢竟,公司為此投入了巨大的資金和人力。
朋友們,當我們管理起公司寄予厚望的雲計算平台時,當我們面對如此多充滿挑戰的實際問題時,該怎麼辦?
概述
我們在搭建趨勢雲計算平台時,遇到了很多的問題和挑戰。開始搭建時,第一次來了那麼多性能強勁的機器,我們在感到興奮的同時,也不免有些顧慮。大家坐在一起討論,問題就列了滿滿一白板。
出了問題怎麼辦,有沒有預警機制?
有沒有可視化的管理界面?
管理平台需要自己開發嗎?開發難度有多大?
紅色部分清楚地標註有問題的機器,點開鏈接,就可以得到有問題機器的情況。雖然在HBase中,幾台RegionServer宕機不會對整體服務產生大的影響,但多少會影響到系統的Performance。而且,如果某幾台RegionServer頻繁宕機,對整個系統的穩定性也會產生不好的影響。有了Nagios,我們可以快速定位有問題的機器,及時地將一些機器移除出HBase系統,待調整好了再上線運行,以保證系統的穩定性。
現在,Nagios已經成為了很多公司必備的監控工具。只需要簡單地配置,就可以實現強大的功能,將管理員從日常煩瑣的工作中解放出來。
有了Nagios,哪怕就是管理上千台機器,也不會手忙腳亂,而是有一種統領千軍、運籌帷幄的感覺。
Ganglia:看到雲計算平台的方方面面
Nagios的確不錯,但你是不是真的可以喝茶、釣魚、睡大覺呢?顯然還不行。有了Nagios,你基本上可以做個優秀的救火隊員,能在事發第一時間到達現場、處理事故。但如何防患於未然,真正做到運籌帷幄、遊刃有餘呢?
我們需要更加精確的數據,能夠看到雲計算平台的方方面面,能根據這些數據,做出性能調整、升級、擴容等的決策,從而保證Service能夠滿足不斷增長的業務需求。
這時候,你需要Ganglia。
Ganglia是UCBerkeley發起的一個開源實時監視項目,用於測量數以千計的節點,為雲計算系統提供系統靜態數據以及重要的性能度量數據。Ganglia系統基本包含以下三大部分。
Gmond:Gmond運行在每台計算機上,它主要監控每台機器上收集和發送度量數據(如處理器速度、內存使用量等)。
Gmetad:Gmetad運行在Cluster的一台主機上,作為WebServer,或者用於與WebServer進行溝通。
GangliaWeb前端:Web前端用於顯示Ganglia的Metrics圖表。
Hadoop和HBase本身對於Ganglia的支持非常好。通過簡單的配置,我們可以將Hadoop和HBase的一些關鍵參數以圖表的形式展現在Ganglia的WebConsole上。這些對於我們洞悉Hadoop和HBase的內部系統狀態有很大的幫助。
在Hadoop的conf文件夾下面,找到hadoop-metrics.properties,配置好Ganglia的Server即可。這裡要注意,Ganglia3.0和Ganglia3.1的區別,它們使用了不同的class。
dfs.class=org.apache.hadoop.metrics.ganglia.GangliaContext31dfs.period=10dfs.servers={Ganglia_Server}:8649
有了這些圖表,Hadoop和HBase就不再是一個黑盒。無論是Hadoop的Namenode、Datanode,還是HBase的MasterServer、RegionServer任何時刻的情況,都會一目了然。由於圖標的跨度可以是小時、天、月甚至是年,這樣,就可以非常方便地定期生成周報、月報和年報。同時,根據圖中Metrics的狀況,我們可以通過調整參數、增加內存和硬碟、增加機器等的方法調整單個機器或者整個Service的性能。
有沒有開源的管理工具?
那麼多日誌分佈在各個機器上,有沒有更有效的方法管理?
能否生成好的報表?
機器宕機,管理員能否收到簡訊通知?
如何做性能調優?
擴容升級時,能否給出依據?
帶著這些問題,我們開始了自己的雲計算平台管理和運營之旅,一路走來,收穫頗豐。現在基本上形成了如圖1所示的一整套雲計算平台監控體系。
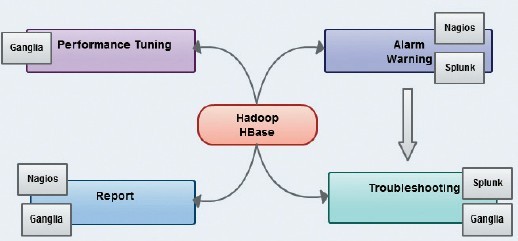
圖1雲計算平台監控架構
在這個系統中,我們綜合利用了Nagios、Ganglia和Splunk,搭建起雲計算平台監控體系,使其具備錯誤報警、性能調優、問題追蹤和自動生成運維報表的功能。有了這套系統,我們終於能夠輕鬆管理Hadoop/HBase雲計算平台了。接下來將簡單介紹它們的特點和功能。
Nagios:雲計算平台的智能報警器
總不能天天盯著機器看吧,因此我們首先關心的是機器的監控與報警。最理想的境界是:如果機器出故障了,我能第一時間處理;如果機器沒有問題(最好永遠沒有問題),我能去喝茶、釣魚和睡大覺。
發現機器有沒有問題,對我們而言不是什麼難事。寫個腳本,Ping一下IP,Telnet每台機器的Service埠,如果增加了新機器就改改配置即可。但這樣也太原始了吧,可視化效果差,不好維護,沒有層次,不好管理,出不來報表,總不能老是用Excel人工寫報表吧。有沒有更好的方法呢?
有,你可以用Nagios。
Nagios是一個可運行在Linux/Unix平台之上的開源監視系統,可以用來監視系統運行狀態和網路信息。Nagios可以監視所指定的本地或遠程主機以及服務,同時提供異常通知功能。
Nagios可以提供以下幾種監控功能。
監控網路服務(SMTP、POP3、HTTP、NNTP、Ping等)。
監控主機資源(處理器負荷、磁碟利用率等)。
簡單的插件設計使得用戶可以方便地擴展自己服務的檢測方法。
并行服務檢查機制。
具備定義網路分層結構的能力,並使用“parent”主機定義來表達網路主機間的關係,這種關係可被用來發現和明晰主機宕機或不可達狀態。
當服務或主機問題產生與解決時將告警發送給聯繫人(通過電子郵件、簡訊、用戶定義方式)。
具備定義事件處理功能,可以在主機或服務的事件發生時獲取更多問題定位。
自動的日誌回滾。
可以支持並實現對主機的冗餘監控。
可選的Web界面用於查看當前的網路狀態、通知和故障歷史、日誌文件等。
Nagios最好用的地方就是它將這些每天管理員做的工作自動化,你只需設定好要監聽的埠即可,它會默默地工作,幫忙定時地去檢測服務埠的狀態,一旦發現問題,會及時發出報警。報警可以是電子郵件也可以是手機,從而使得管理員第一時間就能收到系統的狀況。
Nagios的報表功能也很強大。管理員可以很容易地得到每天、每周和每月的Service運行狀況。
[火星人 ] Nagios/Ganglia與Splunk成就雲計算監控體系已經有1113次圍觀
